In a previous article, we introduced a problem for us to solve using different isolation patterns for Microservices. Wel also examined the traditional way of achieving this via HTTP or RPC. Another option is to make the system reactive.
There really should be no reason why the Comment Service (or any other service) should know of each other’s existence. In reality, the only service they should be cognizant of is the Identity Service, which the Front-end services communicate with in order to validate the user’s token. Beyond the Identity service, each individual service should not be privy to the existence or needs of each other.
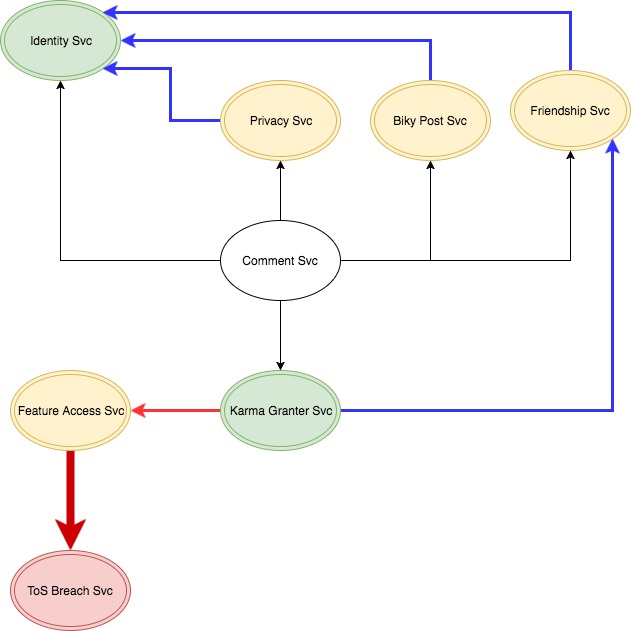
Consequently, each service should be solely focused on fulfilling their responsibilities without explicitly assisting one another. That means services should not call each other in order to trigger some sort of action. They should also not query each other’s data, be it directly or through HTTP/RPC calls. They should fully own their data and their destiny. However, in the rare instances where an explicit targeted call must be made, it should be done in a Location Transparent fashion.
But then, how would we implement those 4 features? Event Publication with a hint of data duplication or caching.
Upon completion of any state changing action, each service within the system would publish event. That event would contain information about what was done (which can be inferred from the type), as well as information deemed pertinent. Any service that would be interested in that type event would subscribe to its source (e.g. RabbitMQ topic, Kafka topic, WebSphere MQ subscription, etc..), and react to the event either by storing data it would need for future actions, or by performing an action.
For example, whenever a user edits his account preferences, the Privacy Preferences service would publish a AccountPreferencesChanged event that would hold information other services could be interested in.
case class PrivacySpecification(onlyFriendCanComment: Boolean)
case class AccountPreferencesChanged(accountId: UUID,
privacy: Option[PrivacySpecification],
updatedAt: Long)Likewise, whenever a friendship is established, the Friendship service could be a NewFriendshipEstablished event.
case class FriendshipRequester(accountId: UUID)
case class FriendshipRequestee(accountId: UUID)
case class NewFriendshipEstablished(requester: FriendshipRequester,
requestee: FriendshipRequestee,
establishedAt: Long)Whenever a comment is posted, a CommentPosted would be created. Whenever a Biky Post is liked, a BikyPostLiked event would be published. Essentially, every time a state changing action occurs, an event would be produced that can be consumed by external interested parties. Consequently, implementing features 1 to 4 is now trivial.
For feature #1 and #4, within the bounded context of the Comment Service, a data ingestion service would exist that would subscribe to different events, namely the NewFriendshipEstablished, FriendshipRescinded, AccountPreferencesChanged, BikyPosted, and the BikyDeleted events. That service would store information relevant to the Commenting bounded contexts in a schema shared only be services within that bounded context. With that done, the Comment Service would no longer need to query data by calling the Friendship service, the Privacy Preferences Service or even the Biky Post Service. It would query its own data store to check upon the existence of the Biky, to validate the privacy preferences of the users with regards to commenting, as well the relationship between user x and user y.
The Karma Granter Service would no longer depend on anyone as well. In the Karma bounded context, a data ingestion service would listen to different events such as NewCommentPosted and BikyLiked to determine the karma score.
The Feature Access service and the ToS Breach Service would both listen to a NewKarmaScoreComputed event. When that score is less the -50, the Feature Access Service would know to publish a message that would be consumed by a Service in the Account Management bounded context to temporarily lock the account’s access to some features by setting a flag one the object that each service gets when they decode the bearer token, and then send an e-mail alerting the user. Based on the NewKarmaScoreComputed event, the ToS Breach Service would know to immediately start its investigation.
What if the ToS Breach Service goes down? While breaches of the Terms of Service by a user won’t be detected until it comes back up and recovers its unacknlowledged messages, the remaining services would continue to operate independently. With this approach, the outage of one service would no longer bring down multiple parts of the system.
What? Duplicated data?
Perhaps you’re concerned about the duplication of data. As developers, the removal of duplication is ingrained in our brain. Plus, it comes at a cost: space.
Disk space is cheap, RAM…not so much. However,wWhat is definitely expensive is losing customers. Many nice articles have been written about duplication such this one by Udi Dahan or this one by Sandi Metz. While those articales are primarily talking about code duplication, I find the points they raise to also be applicable to data duplication. Keeping data seperate and duplicated like this ensures you can use the right database engine (the right abstraction) for your service and fully model all the data a logical service would operate on.
What about data consistency?
Another concern is consistency. There will be a period of time during which the data held by the different data stores will be out of sync before eventually being up-to-date. This is called eventual consistency, two words that make some folks cringe. Part of the reason for it is that we often look at it in terms of consistent versus eventually consistent data, whereas we really should be looking at in terms of operability and performance.
You can have a system that is consistent ALL the time across all components, but that comes with the risk of it not being scalable and not even being operable when one of its components is down. Or you can have a system that IS consistent but with a small delay (ideally), and is still be operable and performant even when multiple of its components are down. Udi Dahan and Greg Young wrote some nice articles on this topic years ago that are still relevant today.
In my opinion, if you can afford the operational cost of Microservices, investing in making your system reactive is the way to go.
You don’t necessarily need Message Queueing systems like RabbitMQ or Kafka to achieve this. You could achieve a similar result using something like Akka Cluster. The one thing to note however is that, as a consequence of using RPC, the delivery guarentee will be At Most Once, whereas using RabbitMQ, Kafka or most other Message Queueing Systems will give you an At Least Once delivery guarantee.
With that said, there is an alternative we have briefly hinted. One extreme option to implement all of our features without concern for other services being down is to blatantly ignore the service boundaries and query the needed data directly in the database. Don’t do this. If you’re tempted to do it, you should really think extra hard about it….and then still not do it. It’s a trap. 99 problems lie in wait behind this door and you don’t to have to solve even 1 of them. Don’t open it. Try to avoid it. Very few cases like ETL may warrant such an approach, but even for such scenarios there are other possibilities. I shall explain how in a future post.